쓰면서 고친다 — 피드백 30여 건과 한글 변환 삽질기 (ICEPDF #3)
썸네일 버그부터 아크로벳식 OCR 텍스트 레이어까지. 그리고 끝내 안 돼서 '빼기로 결정한' 한글 레이아웃 유지 기능 이야기.
첫 버전이 나온 뒤가 진짜 시작이었다. 실제 PDF로 써보면 늘 새로운 게 보인다. 실제 잡지·전자책 파일로 테스트하며 피드백을 라운드로 쏟아냈고, AI와 함께 한 건씩 고쳐나갔다. 30건 넘는 수정 중 기억에 남는 것들만 적는다.
직접 쓰니 바로 드러난 것들
- 썸네일이 1~29쪽만 안 보였다. 원인은 이미지 캐시가 화면에 떠 있는 썸네일의 메모리를 너무 일찍 회수한 것. 캐시를 고치고 썸네일 목록을 가상화해 해결.
- "이전 페이지" 버튼이 안 먹었다. 다음은 되는데 이전만. 네비게이션 로직을 통째로 손봤다.
- 연결 프로그램으로 PDF를 더블클릭하면 프로그램만 뜨고 파일이 안 열렸다. 실행 인자·드래그드롭 처리를 붙였다.
아크로벳처럼 다듬기
이모지 아이콘을 단색 라인 아이콘으로 바꾸고, 형광펜 끝을 둥근 모양에서 각진 모양으로(아크로벳식), 지우개·이미지 커서를 일러스트처럼, 스페이스바 손도구, 두쪽 보기(표지는 오른쪽 단독), 슬라이드 보기, Ctrl+L 전체화면까지 붙였다.
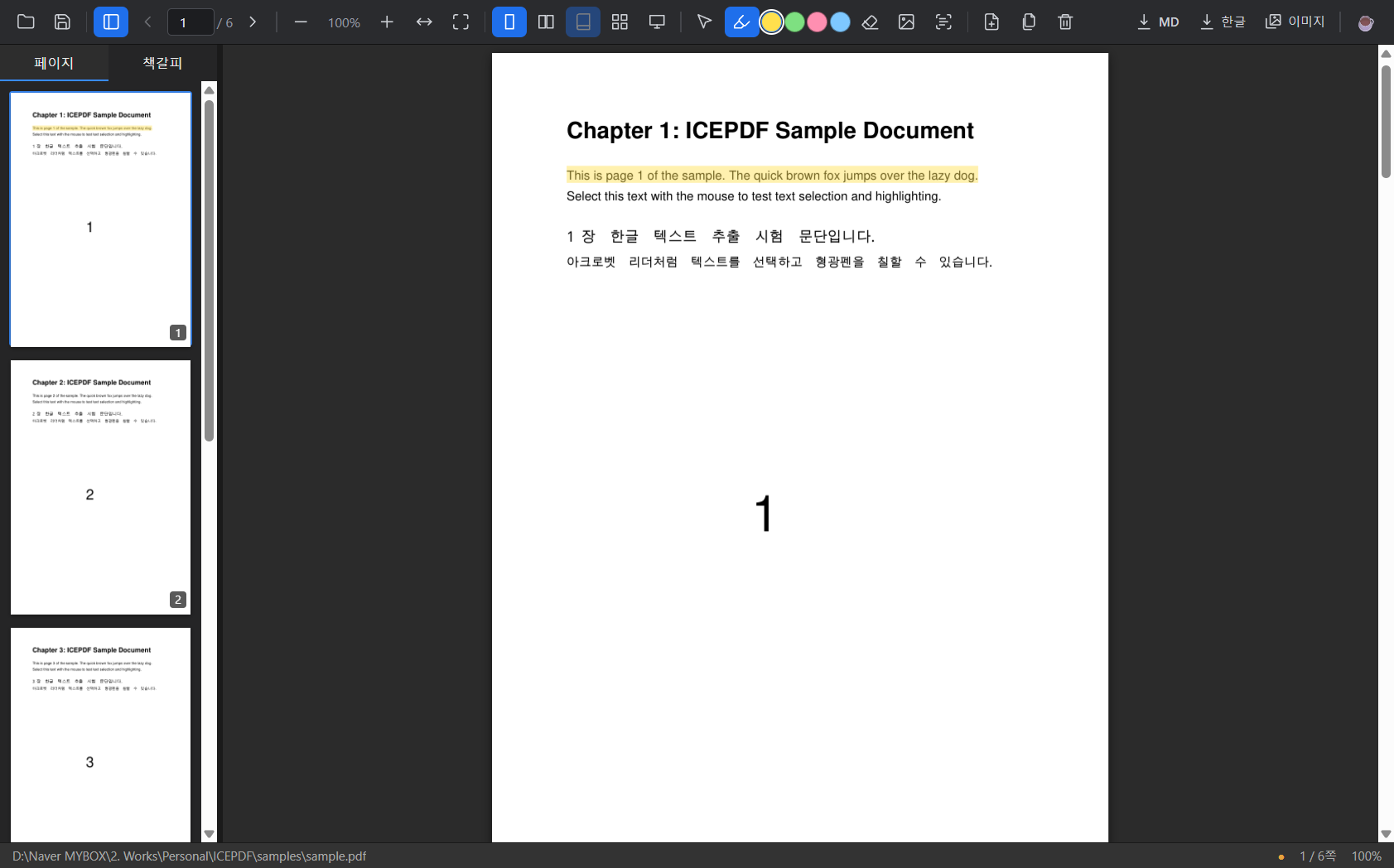
OCR — 아크로벳식 텍스트 레이어
이미지로 된 PDF는 글자를 못 고른다. 그래서 OCR(tesseract.js, 한국어+영어)을 붙이되, 결과를 별도 창에 보여주는 대신 아크로벳처럼 페이지 위에 보이지 않는 선택 가능한 텍스트 레이어를 깔았다. 모양은 그대로 두고, 그 위 글자를 드래그해 복사한다. 현재 페이지·범위·전체 중 골라 인식할 수 있다.
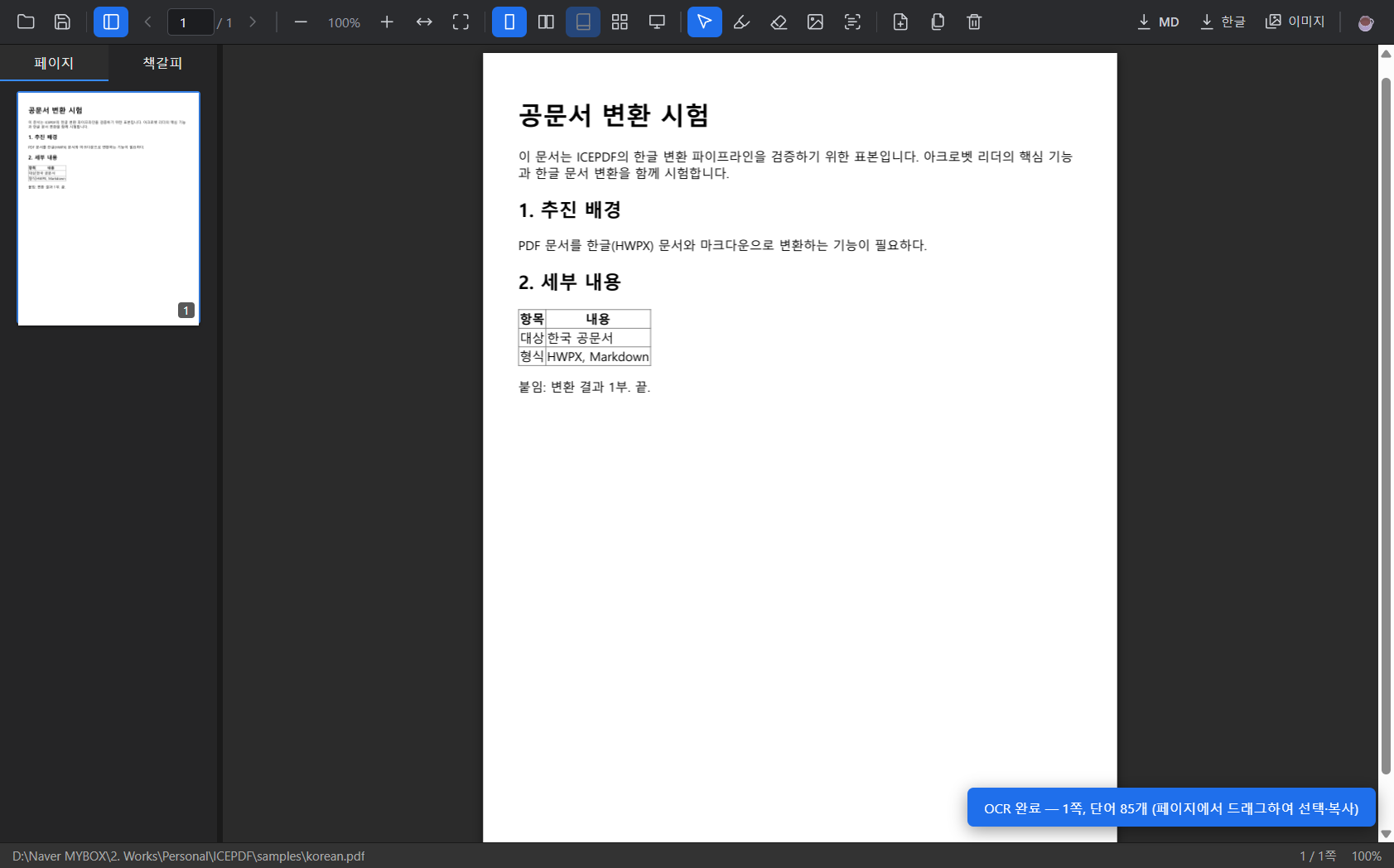
가장 큰 삽질 — 한글 "레이아웃 유지"
여기서 솔직해야겠다. "PDF 레이아웃을 그대로 유지한 채 한글로 보내기"는 끝내 깔끔하게 안 됐다.
한글 문서(HWPX)는 글자가 흐르는 워드프로세서라 PDF처럼 위치가 고정돼 있지 않다. 텍스트를 글상자로 좌표에 박아 넣어 봤지만, 내가 만든 글상자 구조를 한컴오피스 한글이 규격 위반으로 보고 파일을 열다가 닫아버렸다. 검증 환경에 한글이 없어 추측으로 고치다 두 번 실패했다.
결국 판단을 내렸다. "안 되는 걸 억지로 끌고 가지 말자." 레이아웃 유지 기능은 제거하고, 대신 ① 한글 변환은 "텍스트+이미지를 순서대로" 추출(내보내기 전 레이아웃은 유지되지 않는다고 팝업으로 안내), ② 레이아웃을 그대로 보려면 각 페이지를 이미지로 폴더에 내보내기, 이렇게 정직한 두 갈래로 정리했다. OCR도 "이미지 디자인·해상도에 따라 완벽하지 않다"고 미리 안내한다.
기능을 더하는 것만큼 빼는 결정도 중요했다. 다음 글은 이걸 1.0으로 마무리하고 공개한 이야기다.